
House Price Prediction (Kubeflow)
Project Description
Click here to visit github repo
This project focuses on using Kubeflow Pipeline to facilitate house price prediction model development without getting into model building methodology details. Google’s team recommends Kubeflow as the preferred pipeline framework, especially for scenarios where your script does not utilize TensorFlow or manage large datasets, makes your pipelines easier to reuse. You can either create custom components or use existing ones. Due to my local resource constraints, Kubeflow is utilized up to model storage. Deployment involves Kubernetes with Docker, FastAPI, and Supervisorctl for the continuous operation of the API.
- Develop a Kubeflow Pipeline for model training and storage.
- Deploy the trained model on Kubernetes Locally. (unittest and loadtest script provided)
Include a Streamlit file for user interaction. If you opt to deploy on Google Cloud Platform (GCP), you can use App Engine for lower price and ease of management compared to Cloud Run. 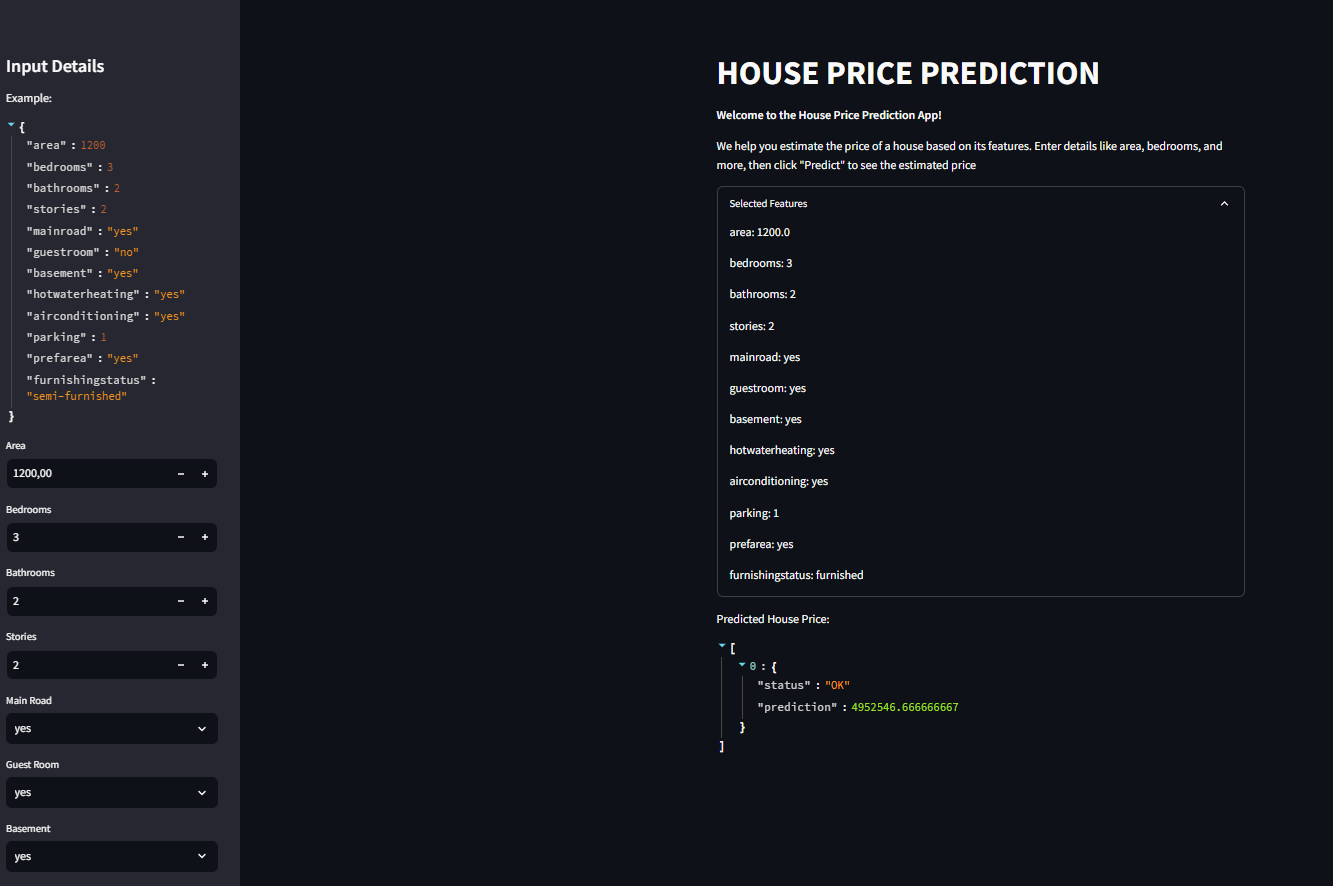
Developing a Kubeflow Pipeline for model training and storage
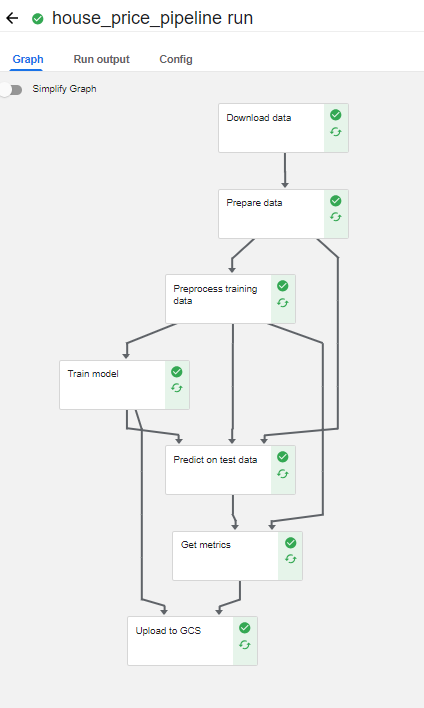
- Download data
- Prepare data (split into train test df)
- Preprocess training data
- Train model
- Predict on test data
- Get metrics
- Store model to GCS
Deploying the trained model on Kubernetes
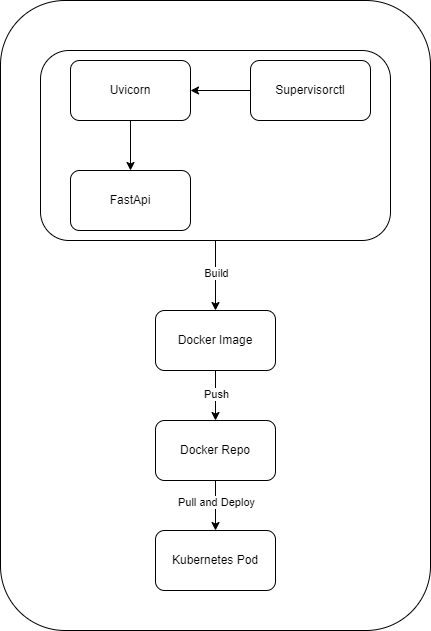
- Creating FastAPI Application and Utilizing Uvicorn

- Configuring supervisor
- Building and Pushing Docker Image to Hub
- Deploy to kubernetes

- Execute the images within pod and sending request to it
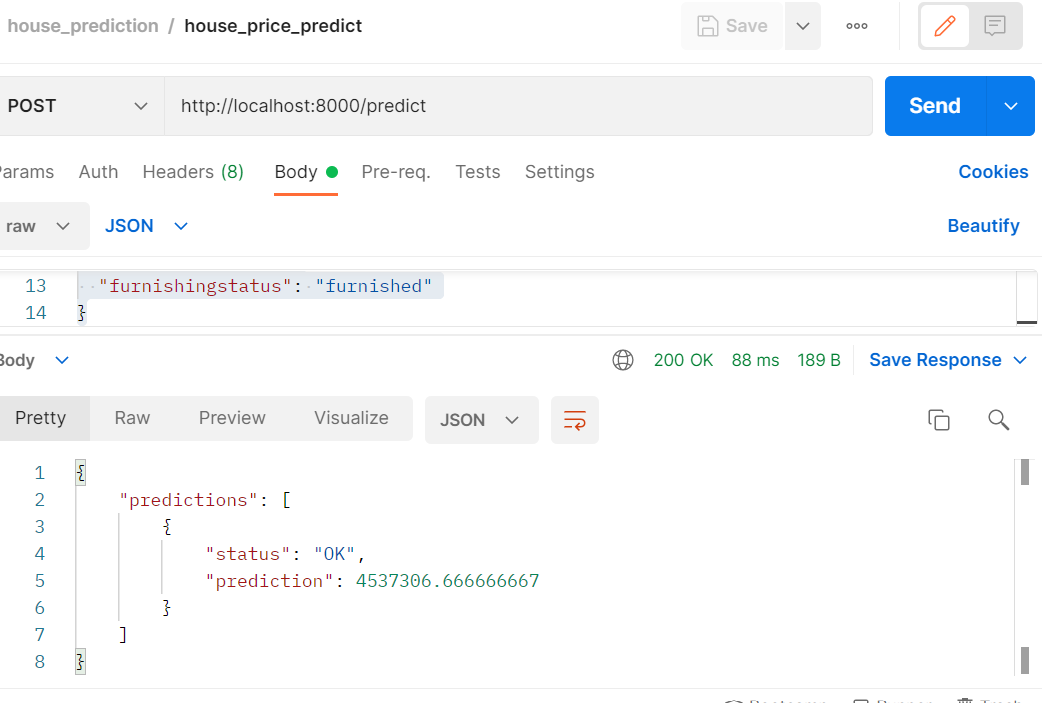
Load test tried 2 scenarios in locust,
- the number of users = 50 & spawn rate = 2 & duration 2m
- the number of users = 10 & spawn rate = 1 & duration 2m
where
- Number of Users: This determines the total load on the system being tested. More users mean more simultaneous interactions with the system
- Spawn Rate: This controls the rate at which users are introduced into the system. A higher spawn rate means more users are added quickly, ramping up the load on the system faster
 given chart, it shows that the response time increases a lot when running with 50 users (95th percentile ~4000ms) but when running with 10 users, it gets faster (400ms). For thorough analysis, we can compare the cpu usage and memory usage between those 2 scenarios. But for now, I’d say the system works well up to 10 users.
given chart, it shows that the response time increases a lot when running with 50 users (95th percentile ~4000ms) but when running with 10 users, it gets faster (400ms). For thorough analysis, we can compare the cpu usage and memory usage between those 2 scenarios. But for now, I’d say the system works well up to 10 users.
BTW I dont cover secret and load balancer, but for those interested in setting load balancer up on your local, try metallb
category: