
App review scraping ETL (Sentiment Analysis)
Project Background & Description
Click here to visit github repo
The JMO app plays a vital role in helping Indonesians access social security programs, including Employment Injury Security (JKK), Death Security (JKM), and Old-Age Security (JHT), provided by the Indonesian government. Ensuring the app’s smooth functioning is imperative not only to meet users’ needs but also to uphold government’s reputation for reliable social security services.
This project not only focuses on deriving insights but also on enhancing the app’s functionality through technological advancements. By leveraging tools like Airflow and KubernetesPodOperator, we aim to streamline the ETL process, including tasks app store review scraping. Additionally, we apply LDA model that we developed to the negative reviews to identify reasons behind negative reviews. The KubernetesPodOperator is particularly valuable in avoiding dependency conflicts, ensuring smooth execution of tasks within the ETL pipeline.
Futhermore, leveraging the data stored in BigQuery will allow us to monitor key metrics through a dashboard.
Infrastucture & Project Steps 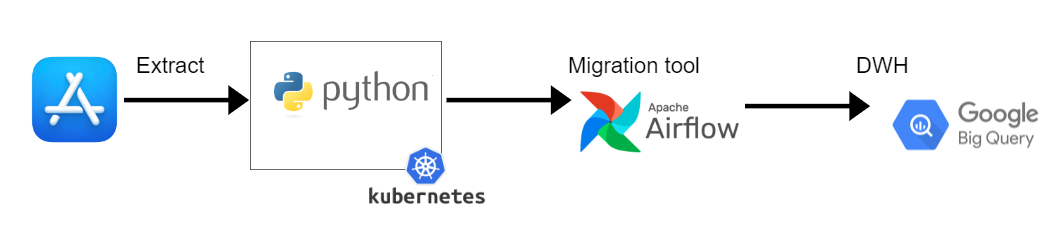
- Develop a module to collect review data from the App Store and use the LDA model to identify reasons for negative reviews
- Build docker image
- Kubernetes Operator generate a request
- Kubernetes will launch your pod according to the specified specifications
- Images will be loaded with all the necesssary config
- After the job is executed, data is stored in BigQuery.
Model development
Data preparation: lowercasing, removal of non-alphabetic characters, stopword removal, stemming, and addressing common typos in the Indonesian, tokenization of the cleaned data facilitates the preparation of the data for model development
Model: Latent Dirichlet Allocation. It’s used for topic modeling, which identifies hidden topics within a collection of documents. The algorithm assumes that each document is a mixture of various topics, and it works by iteratively assigning words to topics and refining its assignments based on word frequencies and distributions across documents patterns in the data.
After experimenting with various numbers of topics for (LDA) and visualizing the results, I have decided to proceed with 3 topics. This decision comes after observing significant topic overlap and complexity in the visualization when using a higher number of topics.
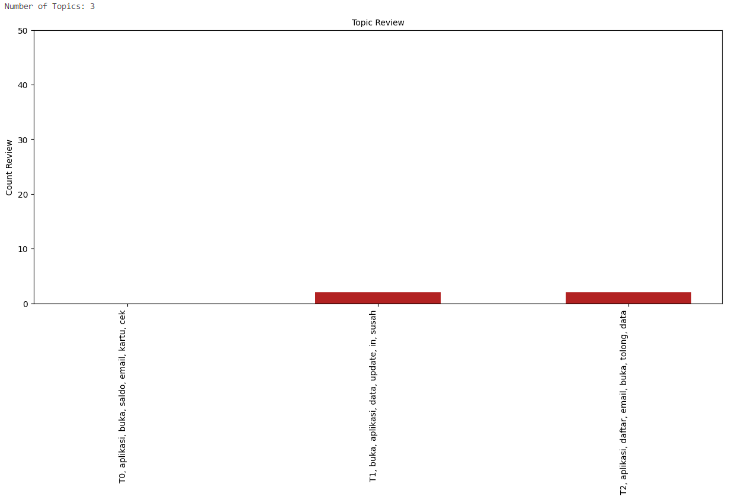
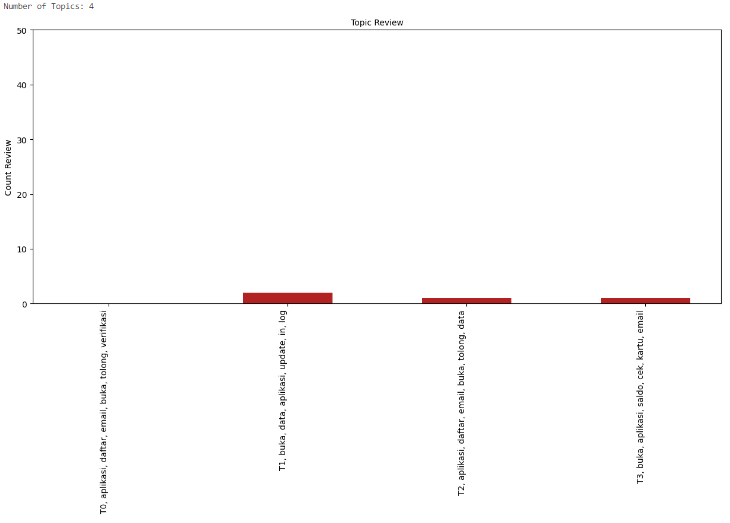
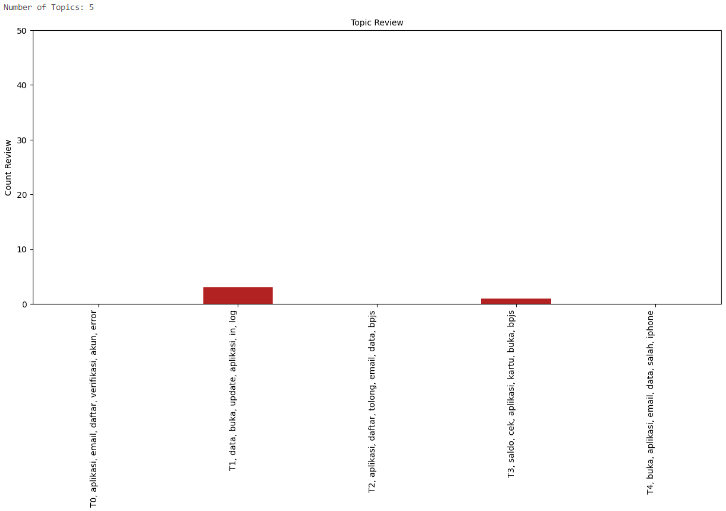
DAG Monitoring
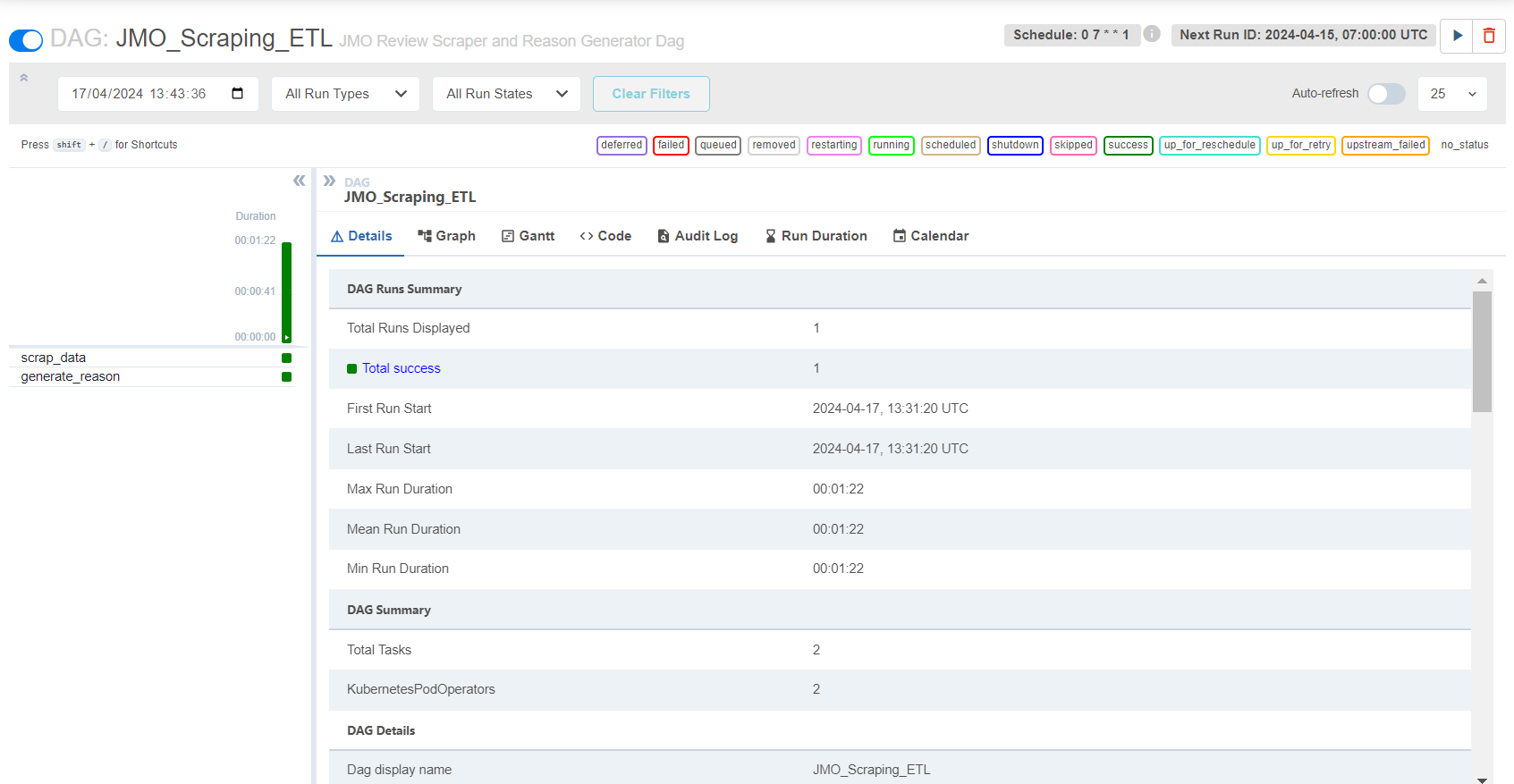 github for details (schedule: every monday)
github for details (schedule: every monday)
Example Dashboard
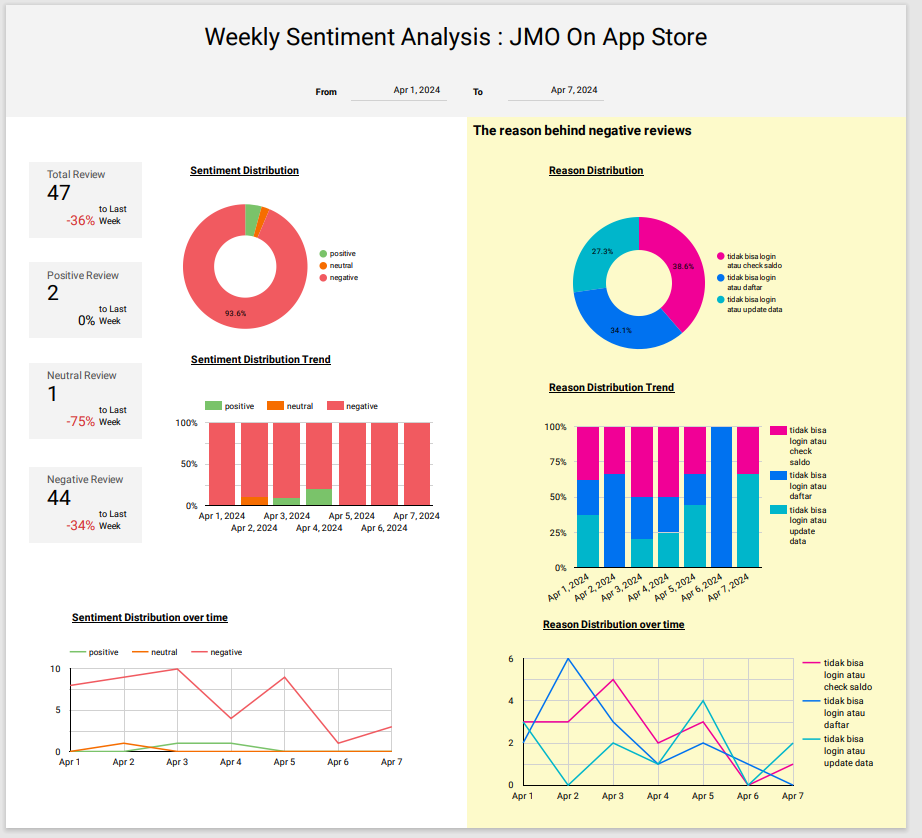 Reason type based on color:
Reason type based on color:
- pink = unable to login or check balance
- blue = unable to login or register
- green = unable to login or update data
Further Improvement
Improve our data cleansing process since we’re dealing with mixed-language (Indonesian or English), perhaps we perform languange detection and split the reviews into groups based on language and process data accordingly
category: